Openclaw 接入 Nonelinear
概述
本文档将指导你在服务器上安装 OpenClaw,并接入 NoneLinear 统一 API 平台。通过 NoneLinear,你可以用一个 API 接入点调用多家主流大模型厂商的模型,包括 OpenAI、Anthropic、Google、DeepSeek、字节豆包等。 NoneLinear 同时支持两种协议接入:- OpenAI 兼容协议
- Anthropic 原生协议
前置要求
- 一台 Linux 服务器(Ubuntu/CentOS/Debian 等主流发行版)
- Node.js 环境(建议 v18+)及 npm
- NoneLinear 平台的 API Key(获取 API Key)
一、安装 OpenClaw
Step 1 全局安装 OpenClaw
Step 2 初始化配置
运行 quickstart 向导,完成基础配置并安装守护进程:
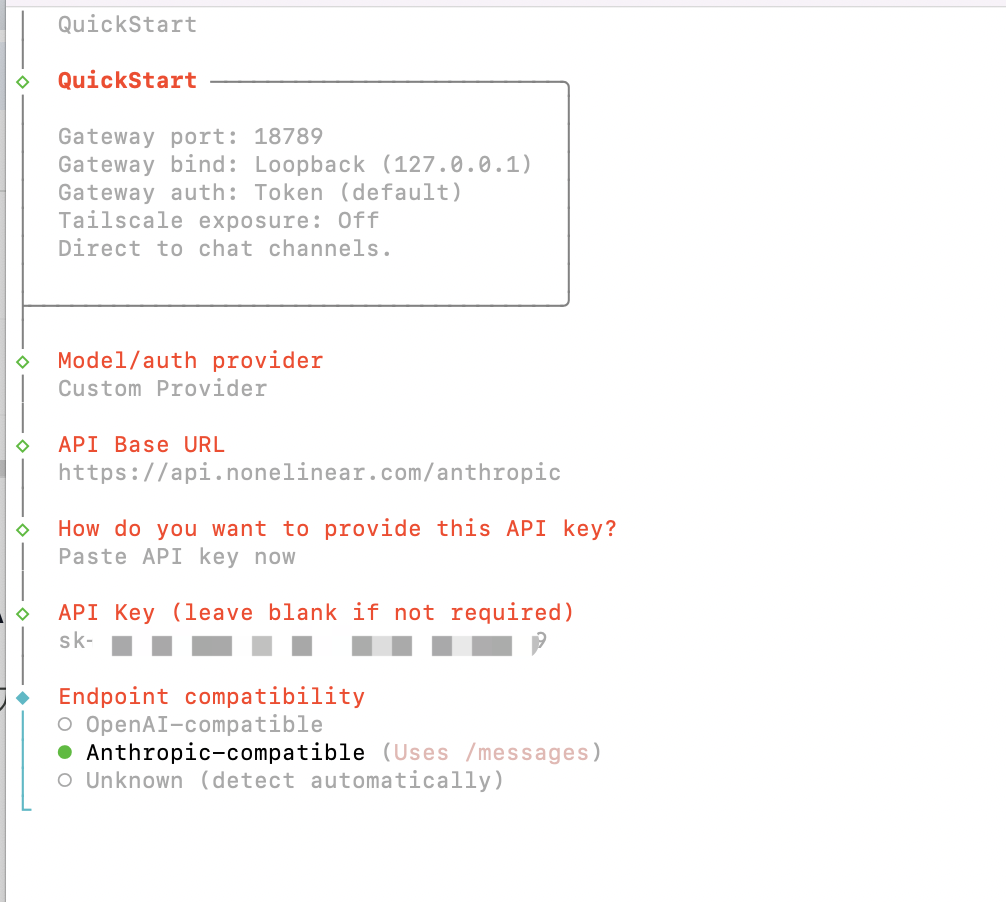 QuickStart中的 Model/auth provider 步骤,选择 Custom Provider(Any OpenAI or Anthropic compatible endpoint),然后按以下方式填写(以 Anthropic 格式为例):
QuickStart中的 Model/auth provider 步骤,选择 Custom Provider(Any OpenAI or Anthropic compatible endpoint),然后按以下方式填写(以 Anthropic 格式为例):
| 字段 | 填写内容 |
|---|---|
| API Base URL | https://api.nonelinear.com/anthropic |
| API Key | 你的 NoneLinear API Key |
| Endpoint compatibility | Anthropic-compatible(OpenAI格式的就选OpenAI-compatible) |
| Model ID | NoneLinear 模型广场,例如 claude-haiku-4.5 |
注意:
- QuickStart中的配置仅用于验证,后续配置多模型、多Agent等,会通过修改配置文件进行完整覆盖。
- 如果 channel 部分选择飞书的,可以参考 相关教程。
Step 3 停止网关
在修改配置文件前,先停止网关服务:二、配置 NoneLinear API(OpenAI 兼容协议)
这是最常用的接入方式,使用 OpenAI Chat Completions 兼容的协议格式。所有通过 NoneLinear 接入的模型均可使用此协议。方法一:编辑配置文件
打开配置文件:关键字段说明:
baseUrl设为https://api.nonelinear.com/v1api字段设为"openai-completions"apiKey使用环境变量引用${OPENAI_API_KEY}
方法二:命令行配置
如果你更喜欢用命令行,也可以直接运行:三、配置 NoneLinear API(Anthropic 原生协议)
如果你需要使用 Anthropic 原生协议,配置方式与 OpenAI 协议几乎一模一样,只需修改两个字段:| 配置项 | OpenAI 兼容协议 | Anthropic 原生协议 |
|---|---|---|
| baseUrl | https://api.nonelinear.com/v1 | https://api.nonelinear.com/anthropic |
| api | openai-completions | anthropic-messages |
配置文件示例
命令行方式
四、启动与验证
Step 1 重启网关
Step 2 探测模型可用性
Step 3 查看整体状态
五、多模态能力扩展
完成上述基础接入后,OpenClaw 已经具备文本对话能力。如果你需要让 agent 能”看图、画图、生视频”,本节将逐步介绍如何在前面配置的基础上启用三类多模态能力:视觉理解、图像生成、视频生成。OpenClaw 多模态架构提示:OpenClaw 通过四个独立字段控制多模态路由:
agents.defaults.imageModel— 视觉理解(看图)agents.defaults.pdfModel— PDF 理解agents.defaults.imageGenerationModel— 图像生成(画图)agents.defaults.videoGenerationModel— 视频生成
agents.defaults.model,允许”主聊天用便宜模型,多模态调用切到能力更强的模型”。1. 视觉理解(看图)
视觉理解是最简单的多模态能力,只需在模型声明中加一个input 字段即可启用。
工作机制
当用户发送图片时,OpenClaw 检查当前会话使用的模型是否在models[].input 中声明了 "image":
- 声明了 → 直接把原图作为原生输入传给该模型
- 没声明 → 路由到
agents.defaults.imageModel.primary指定的视觉专用模型处理
配置示例
在前面接入配置的基础上,给模型加input 字段,并配置 imageModel:
关键字段说明:
input数组合法值:"text"/"image"/"audio"/"video"imageModel.primary仅在主模型不支持视觉时才会被使用pdfModel未配置时自动 fallback 到imageModelimageMaxDimensionPx(默认 1200)控制传入模型前的等比下采样上限
验证视觉理解
2. 图像生成(画图)
OpenClaw 的图像生成走image_generate 工具,由 agents.defaults.imageGenerationModel 字段控制。
接入方式:覆写 openai provider id
配置说明:
imageGenerationModel.primary写成openai/gpt-image-2—— 此处openai是 OpenClaw 内部的 provider id(已被baseUrl覆写指向 NoneLinear),不是字面 OpenAI;gpt-image-2是 NoneLinear 上架的模型 ID。- 模型 ID 必须与 NoneLinear 模型广场 上架的名称完全一致。
timeoutMs默认 60 秒,建议提到 180000(3 分钟)以覆盖大尺寸图像生成。
配置多 Provider fallback 链
NoneLinear 模型超市同时上架了多家图像生成模型,可通过 fallback 链实现自动容错:工具参数清单
agent 调用image_generate 时可用以下参数(绝大多数由 LLM 自动决定):
| 参数 | 说明 |
|---|---|
prompt | 图像描述提示词 |
model | 单次调用覆盖默认模型 |
image / images | 编辑参考图(最多 5 张) |
size | 1024x1024 … 3840x2160 |
aspectRatio | 1:1 / 16:9 / 9:16 等 |
resolution | 1K / 2K / 4K |
outputFormat | png / jpeg / webp |
count | 1-4 张 |
timeoutMs | 单次调用覆盖超时 |
验证图像生成
3. 视频生成(生视频)
视频生成走video_generate 工具,由 agents.defaults.videoGenerationModel 字段控制。
配置示例
timeoutMs 设置为 600000(10 分钟)是因为视频生成普遍较慢,Sora 通常需要 2-5 分钟。三种生成模式
agent 调用时支持三种模式:| 模式 | 输入 | 用途 |
|---|---|---|
generate | prompt | 文生视频(T2V) |
imageToVideo | prompt + images[] | 图生视频(I2V) |
videoToVideo | prompt + videos[] | 视频续写/风格化 |
aspectRatio、resolution(480P/720P/1080P)、durationSeconds、audio(是否生成音轨)、watermark、providerOptions(如 seed)。
异步任务总线
视频生成是异步的,OpenClaw 内部走”后台任务 + 会话 wake event”模型:- agent 调
video_generate→ 立即返回task_id,状态queued或running - Provider 在后台跑(30 秒到 5 分钟)
- 完成时 OpenClaw 注入 internal completion event,唤醒同一会话,agent 在新一轮对话以附件形式 post 视频
- 状态机:
queued→running→succeeded/failed
多视频模型 fallback
如果 NoneLinear 同时上架了 Sora、Kling、Wan、Veo 等多家视频模型:验证视频生成
六、多模态完整配置示例
下面是一份生产级完整配置,集成基础接入 + 视觉理解 + 图像生成 + 视频生成,全部路由到 NoneLinear:- 把上面 JSON 写入
~/.openclaw/openclaw.json(先备份原文件) - 运行
openclaw doctor检查配置语法与连通性 - 运行
openclaw gateway restart重启网关 - 运行
openclaw models status确认所有 provider 鉴权通过 - 在已连通的 channel 测试四类调用:
- 文本:直接发文字消息
- 视觉理解:发一张图 + “描述这张图”
- 图像生成:“生成一张赛博朋克风格的城市夜景”
- 视频生成:“生成一段 5 秒的猫弹钢琴视频”
七、多模态故障排查
Q1:Model "nonelinear/xxx" is not allowed
原因:模型未加入 agents.defaults.models 白名单。
解决:在 agents.defaults.models 中显式添加该 key:
Q2:image_generate 工具未出现在 agent tools 中
原因:OpenClaw 没检测到任何已注册的图像生成 Provider。
解决:检查三件事:
agents.defaults.imageGenerationModel.primary已配置- 对应 Provider 的
baseUrl和apiKey已设置 openclaw doctor未报鉴权错误
Q3:图像/视频请求成功但模型返回错误
原因:NoneLinear 上架的模型 ID 与 OpenClaw 内部协议预期的 ID 不一致。 解决:用 curl 直测 NoneLinear API,确认实际模型名:imageGenerationModel.primary 或 videoGenerationModel.primary。
Q4:自定义 baseUrl 似乎没生效
原因:OpenClaw 在~/.openclaw/agents/<agentId>/models.json 维护 per-agent provider 覆盖。如果该文件中已有非空的 apiKey/baseUrl,会优先于全局 ~/.openclaw/openclaw.json。
解决:
当前未覆盖的能力:OpenClaw 的 TTS(语音合成)、STT(语音识别)、音乐生成属于”插件能力槽”,由 OpenClaw 的 Speech Provider / Media Understanding Provider 插件管理,纯配置无法接入。如需让 NoneLinear 的 MiniMax Speech、Whisper 等模型接入这些能力槽,需通过 OpenClaw 的 Plugin SDK 编写插件注册。该能力将在 NoneLinear 官方插件发布后开放。